



Author: Joseph Cazier, Edgar Hassler, James T. Wilkes, Max A. Rünzel, Giovanni Formato, Robert Brodschneider
Many readers of this series in Bee Culture will recall that our first article, titled “Peering Into the Future: The Path to the Genius Hive,” came out in April 2018. In that article we shared that a genius hive is more than a smart hive. It is a hive that takes all the information from a smart hive, integrates best management practices and years of standardized data to guide beekeepers with real-time information that can help predict what the hive needs and optimize its output and productivity.
In this article, we dive deeper into one of the very key ingredients to building a genius hive, or doing any real work with Machine Learning or Artificial Intelligence. That key component is large amounts of standardized data. They call it Big Data for a reason: these operations do in fact take large amounts of data to effectively use them.
Though many common statistical techniques can be done on relatively small data sets, big data is needed for machine learning because, even though there is some overlap, Machine Learning is fundamentally different than classical statistical approaches. Historically, with statistics or traditional programming, you have data and a pre-existing algorithm, that is honed with complex math and trial and error over many years on many data sets, to determine an output. This output could be some function in a program such as Excel, or could be the result of statistical output from an ANOVA, statistical index, computation of means, or other alternatives.
Machine Learning, in contrast, turns this process around (see Figure 1.). Instead of taking the data and a pre-existing algorithm to determine a standard output, it takes the data and creates a new algorithm to explain or predict the already observed output.
Recall that an algorithm can be defined as a process or set of rules to be followed in calculations or other problem-solving operations, especially by a computer. This means that the computer is creating a new process to explain or predict the observed outcome instead of using a pre-developed one. One might imagine, correctly, that developing a new algorithm from scratch on a new data set, like the ones developed over many years of research in statistics, takes these steps: 1) large amounts of data, 2) large computational resources, and 3) very complex math.
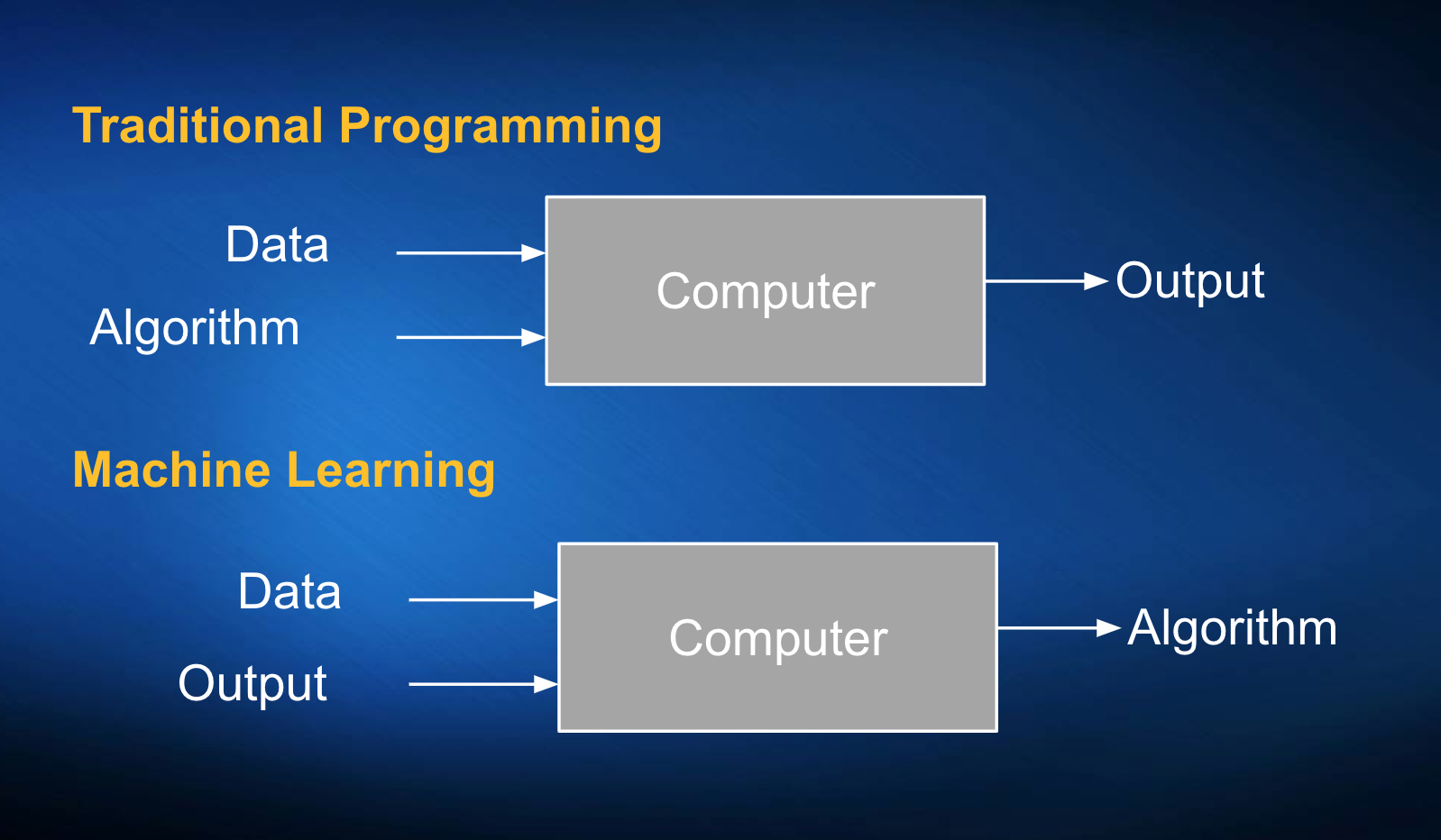
Figure 1. Traditional programming vs Machine Learning.
While it is true that machine learning takes all of these steps, in today’s world, large computational resources are more available than ever before and many complex mathematical techniques have already been developed and proven effective, though more work is still being done to develop newer methods. This means that the key thing we are missing, at least when it comes to bees, is data.
However, in order for data to be useful, it needs to be in the same format so it can be aggregated and fed into the machine to create the proper artificial intelligent algorithms. To be aggregated reliably and effectively, it must first be standardized. In this article, we will define what standardized data is, share a few examples of how standards have transformed society in the past, show the path to building a data standard, share some current challenges to building one, and recommend a clear path forward.
Standardized Data
I recently shared a poster and gave an oral presentation that my colleagues and I have been working on at the annual COLOSS conference in Montreal, Canada just before Apimondia on the topic of data standardization. This article covers most of the key points in the oral presentation. You can see a copy of the poster in Figure 2.

Figure 2: COLOSS 2019 Conference Poster
Standardized data is data that comes with a definition. We know what it means because it has a common, precise definition that anyone familiar with the topic would understand or be able to look up. Because it is defined, we know what it means and can put it together with data from other sources from other times and places. In some cases, conversion from one standard to another, such as the English to the Metric system of measurements or from one language to another is possible. However, in most cases this is much more difficult and with some it is not possible – and even when it is possible, it adds an extra layer of complexity and inefficiency.
Regardless, having and using a standard widely is the key to being able to collect large amounts of data that a machine learning algorithm can use. You will still need to piece it together, clean it, and analyze it, but having a standard makes this process much easier.
In business, you often have one large multinational company or government group that is large enough to acquire sufficient data to use on its own, but does not want to share with others due to competitive pressure, i.e. imagine Walmart sharing with Target?
However, with beekeepers, the situation is different. There is NO organization big enough on earth to do this effectively, at scale, and on a wide variety of topics related to bees, at least not yet. A few organizations might be able to do a piece of something here or there, but there are none that come close to having the whole picture. This situation is not likely to change in the near future for these reasons:
- Small Scale: Despite having a few very large commercial beekeepers, a large portion of the estimated hundred million or so hives in the world are managed by small scale beekeepers. Due to family history, small holder keepers, economics, hobbyist beekeeping for fun, and other factors, this is likely to remain this way for some time.
- Geographic Difference: Even if someone is a large-scale beekeeper, most do not move much beyond their home country, and certainly not continent, on a routine basis. Because our machine learning algorithms need data from many places, even the largest beekeepers will always be missing some key knowledge and insight if they keep only to their own data. Different environments will need to account for those differences in their datasets.
- Genetic Differences: Different hives generally have different genetics.These different lines will have key differences that will need sufficient data for those lines to round out the analytics.
- Management Practices: There are different management practices in different parts of the world. Some of these are necessary due to different environments, but many others are simply due to regional beekeeping customs, which makes it harder to aggregate data from different sources.
- Language: the many languages spoken by beekeepers around the world also make data standardization a challenge.
Unlike the case of the retail giants Walmart vs. Target mentioned above, who would likely not share data due to competitive pressure, beekeepers have much more incentive to standardize and share data. These include:
- Natural Threats: The threats beekeepers face are less from competitors and more from nature. We are not fighting each other so much as threats from the natural world. We need to work together to find solutions.
- Lack of Data: As described above, none of us have, or is likely to have, enough data to adequately address all the problems the bees face. It is only by pooling our data that we can really make the most difference for bees and beekeepers.
- Love of Bees: Most of us are hobbyists and scientists who love bees. We want to learn about them and help them. These groups have a long history of sharing data and information across many disciplines. However, even commercial beekeepers tend to be rather altruistic when it comes to this issue.
- Food supply: As much as we all love bees, we likely love food even more. We have to work together to secure our food supply for all of us and future generations.
Data Standardization Examples
In our article, “BeeXML Part II – Achieving the Goal of Standardized Data,” in the November 2018 Issue of Bee Culture, we went into some detail about the importance of a data standard and some examples. In this article we will just list a couple quickly so we can focus more on how to create a standard.
Here are a few examples of successful standards:
-
Figure 3. An early Illustration of a Langstroth Hive from the book The Hive and the Honey-Bee
Langstroth Hive: Its development along with similar standard hives in the 1850s revolutionized beekeeping. Discovering the importance of “Bee Space” and having standard sizes of hives and frames allowed for the free exchange of equipment, bees, and other materials between hives and beekeepers, making it much easier to scale and manage bigger hive yards. It also considerably lowered production and maintenance costs for hives.
- Healthy Colony Checklist: A human standardized method to assess the health of a hive developed by Dick Rogers and profiled in our July and August 2018 Bee Culture articles, is fast becoming a standard. It has already been adopted by HiveTracks, Broodminder, The World Bee Project, our Center for Analytics Research and Education at Appalachian State University, and others as the default hive inspection tool for health assessments. See Figure 2.
Next we discuss the process of how to build a standard.
Path to Building a Standard
The path to build a data standard includes the following steps.
- Survey Data Space: Surveying and mapping a data space by collecting samples of a large variety of data to identify collectible and viable data elements for evaluation, including a diversity of data from genetics, health, honey testing, and management practices, to name a few
- Data Prioritization: Identifying which types of data are most important to measure and which types have the most value to researchers and beekeepers now
- Measurement Scale: Deciding how best to measure those factors like health assessment, weights, treatment standards, Varroa counts, etc.
- Technical Architecture: Developing the technical architecture for storing, transmitting and analyzing that data in a common format for computer-to-computer storage and harmonization
- Inclusive Governance Infrastructure: Following an inclusive and conscious approach both to govern the process and the output of the standardization in collaboration with practitioners, researchers, Governmental Organizations and the International Organization for Standardization (ISO), in line with ISO’s approach in other fields of research.

Figure 4. Healthy Colony Checklist Developed by Dick Rogers
Next, we turn to some of the challenges we face in building such a standard for bee data.
Current Challenges to Standardization
- Lack of Organized Data: It seems there is a near global lack of good recorded data related to bees and beekeeping, with 74% of respondents in one survey admitting that they do not keep records of their actions but instead rely primarily on memory.
- Data Format: For those who do keep records, most of it seems to be on paper, hive boxes or custom spreadsheets. If the data is not recorded digitally, in a standard format, it is difficult to collect.
- Data Quality: Outside of a few software systems and sensors, most data that is collected outside of rigorous scientific studies tends to have many contextual and data quality issues, making it hard to interpret and standardize.
- Proprietary: Of the data that is collected in a quality manner, such as by software companies, pharma, and some commercial beekeepers, much of it is considered proprietary and a competitive asset of the firm that owns it, which creates a reluctance to share.
- Technical Help: When we do receive or find useful data, it takes time and resources to convert that data to a conceptual standard, and even more to a technical standard, such as BeeXML.
We have a few ideas of how these challenges can be met, perhaps with assistance from organizations like Apimondia, which we present below.
Recommendations
In previous articles in this series (BeeXML Parts 1 & 2 in October and November 2018), we talked about the need for large volumes of data from citizen beekeepers on which to build algorithms. This data is critical to building a large enough data set to effectively train machine learning algorithms.
However, in order to build this data set from beekeepers, we must first identify what data elements are the most important to have to build useful tools for them. To do this effectively (meaning more than just guessing) we first need to collect, harmonize and test a wide variety of quality data that has good annotated records with outcomes. This will minimize the burden on the average beekeeper.
To identify this core and build a standard, we need a much broader swath of data of very high quality. The best place to get this type of data is from researchers who are trained to collect high quality data on a variety of topics with well documented records. The best way to get researchers to share their data is to allow them “academic” credit by publishing it.
We are therefore proposing that some group like Apimondia, COLOSS or an existing bee journal like Bee World or The Journal of Apicultural Research publishes an online open access peer-reviewed journal for bee datasets. This should include accompanying meta-data, and that the journal sees that the BeeXML technical data definitions are created and published to store and transmit this and similar data for future generations to use.

Figure 5. The inspirational general purpose data journal, Data in Brief
There is a similar journal, Data-In-Brief (https://www.journals.elsevier.com/data-in-brief), sponsored by Elsevier that operates on this model for a broad array of data. Bee data is broad and diverse enough that we should have our own dedicated journal for bee data so our data can be defined and stored in one place.
Establishing a bee data journal would help with the challenges we are facing in the following ways:
- Lack of Organized Data: It would create an open public venue for collecting this data, along with an incentive for those currently collecting high quality data, mostly researchers, to share their data as it would count for a peer-reviewed publication based on data collected from their experiments, giving them an academic incentive to participate. This data is ideal in the early days of standard creation due to the high quality of the data and documentation collected by researchers.
- Data Format: In the beginning, data would be collected more or less as defined by the researcher with a good data and process dictionary. During the publishing process, this data could be harmonized and compared with data on similar topics and a standard for similar data will begin to emerge. This format can be published as a recommended standard based on usage, usefulness, and other measures with a guided group recommending it. Finally, this data can be converted into an XML (or JSON) format (technical language for data standards) that can be used to transmit and aggregate data of this type.
- Data Quality: Researchers are also key here in the beginning. Again, their data seems to have the highest quality level and best documentation due to the controlled nature of research. As it is combined and made accessible to other researchers to look at and analyze, more studies can be done on this combined data.
- Proprietary: Even vendors of software, sensors, and testing solutions will have an incentive to share some of their data. It may be anonymized, but by sharing, these vendors might have a team of researchers look at their data and publish insights that their own analysis may have missed, generating goodwill and name recognition. Additionally, vendors’ tools will inevitably be used by researchers who will want to publish at least their slice of that data, allowing for a standard to be built here too.
- Technical Help: Data in Brief, mentioned above, charges a small processing fee to help guide the publication and data storage. This Bee Data Journal could be set up in a similar way, either through subscriptions fees for the data, publication fees to support the effort, or some other funding efforts associated with a publication like this. A portion of these funds could be used to pay for technical services to store the data in an accessible format and convert the data into a technical standard like XML.
In addition to helping address the challenges listed above, there would be several other benefits.
- Wider Adoption: As the journal adopts a standard, other vendors and beekeepers will gradually follow, paving the way for at least aggregate data collection.
- Real Time Info: This collection of data in the standard, perhaps from wider sources, could eventually be automated and used to build reports and create alerts in real time, such as disease monitoring.
- Data Pooling: This data could be pooled so that like studies could more easily be combined with other like data automatically, building an important repository over time.
- Data Bank: This journal would also create a data bank, similar to a gene or seed bank, or cold storage for bio specimen that could archive data for generations to come in a standard format, facilitating long time horizon research and monitoring.
- Data Mining: As a wider dataset grows based on the standard, data mining becomes possible. At first this will be from harmonized research data and eventually real time standardized data from the field from citizen beekeepers around the globe.
- Complete Research Data: Currently, many researchers carry out studies and ask or collect more data than they ultimately publish. All data from experiments could be published, minimizing the wasted effort. As the research articles typically do not publish the data, but just the analysis, and data journals only publish the data without analysis, this is a perfect symbiotic relationship.
- Data Bias: There is believed to be a fair amount of bias in research today as studies finding positive results tend to get published, and those with no results tend to not be published. If the data can still be published, it can be saved and analyzed which would help address some of this bias.
Conclusion
We are pleased with the news that the Apimondia Working Group #15 on Standardization for Bee Data has officially endorsed the recommendation in this article. Hopefully this recommendation will help make this idea become a reality.
This is a unique opportunity to help build a global data standard for data related to bees and beekeeping by supporting the establishment of a Bee Data Journal to collect high quality diverse data leading to an open data standard that can be used for machine learning and data mining to facilitate better beekeeping. Now is the time, please help support these efforts.

Figure 6. A few Groups Supporting Our Work with Data Standardization
Finally, special thanks to Project Apis m. for supporting a portion of this work with a Healthy Hives 2020 grant, Apimondia for supporting our working group, and COLOSS for providing a venue to share this work. Also to the leaders at the Center for Analytics Research and Education at Appalachian State University and HiveTracks.com for sharing their thoughts on this topic. Finally, we also share thanks to the editors of Bee Culture for publishing this work. These efforts would not have been possible without visionary groups like those above providing support and resources.


