




By Joseph Cazier, Walter Haefeker & Edgar Hassler
In Search Of The Genius Hive
Last month, in the October issue of Bee Culture, our article “BeeXML Part I – The Power of Big Data and Analytics,” discussed how and why data science can help bees and beekeepers everywhere by allowing us to analyze data and build support systems to facilitate smarter decisions. This idea builds on, but goes beyond, the concept we called the Genius Hive. A Genius hive incorporates analysis that builds on the base of a smart hive, as well as other standardized data, to provide solutions beekeepers need to optimally manage their hives. By way of review, here are just a few possible gifts from Data Science and the Genius Hive:
- Hive Placement Optimization: Determine the best location to place your bees, optimized for proper forage and environmental conditions for bees, honey production, and crops.
- Status Alerts: Provide updates on the current state of the hive, such as problems with the queen, pests, or pathogens.
- Predictive Alerts: Use predictive analytics to anticipate problems before they start and send alerts.
- Treatment Optimization: Use data from thousands of outcomes of similar hives to guide which treatment options would be most likely to succeed for a given hive under given conditions.
- Trend Analysis: Monitor regional and national trends in real time for better policy and response to incoming threats.
There is much more beyond this to help bees, beekeepers, farmers and society that can be done. However, none of this is possible without the right data, stored in the right way, and accessible with the right tools. The key to this is the development and adoption of a universal data standard for bees and all beekeeping activities coupled with the sharing of that data in a way that can be analyzed, incorporated into tools, and given back to beekeepers and other stakeholders everywhere. There is too much at stake to not take advantage of these tools.
As mentioned in last month’s article, in the Fall of 2017 we formed a working group under the umbrella of Apimondia (Apimondia Working Group #15) focused on “Standardization of Data on Bees and Beekeeping.” This group is working to identify important data, define an XML library, and encourage the creation of an appropriate data collection system to aggregate and analyze the data. This time we will look at how we can achieve this goal of building and adopting a data standard.
 Defining a Data Standard
Defining a Data Standard
Just as there is no perfect or best language, there is no perfect or best data standard. Some are easier to use, some hold different types of information, some are easier to learn and some are easier to move data into or out of. These things do matter from an operational, efficiency, and utility standpoint. Yet what matters most is that it is defined, consistent, and extensible as data needs grow and change.
A good analogy is the story of the Tower of Babel1. According to the legend, at one time mankind was united, speaking one language. In this unified state they tried to build a tower to reach heaven. Depending on the version of the original myth you favor, something happened that caused them to lose the ability to speak the same language. Unable to communicate, the people scattered and were divided again. Their tower fell into ruin as their united effort was lost with the loss of their ability to communicate with one another. Thus we have the phrase, when we cannot understand what someone is saying, that they are babbling – after the story of Babel.2
Translation vs. Standardization
Whatever the historical accuracy of the story, it illustrates a key point. In order for different groups to communicate, they need to speak the same language. While each language may have its own character with its own advantages and disadvantages, we can generally communicate well if we are both speaking English, Spanish, Chinese, Klingon, German or any other language. As long as it is the same, we can generally get the message across. If we are speaking different languages, this becomes much more difficult. Even if we can translate, meaning and efficiency are often lost, slowing down the speed and accuracy of communication.
As it is with the languages people speak, so it is with technical and computer languages. In order to communicate effectively and efficiently, especially in a way that preserves a precise meaning – the kind needed for good Data Science – they need to be speaking the same language with clear semantic (meaning) definitions.
Openness
A standard, on the other hand, is a common language, designed to communicate items precisely. All can adopt it from the start and clearly define each parameter. It can be optimized from the beginning to collect, store, and transmit the necessary data. Ideally it is also one that can grow and adapt to changing needs over time. It should also be open to all so everyone can use it. Unless everyone uses it, it is not a standard.
Building a data standard is not the same thing as adopting whatever platform the winner or first system uses. It is about thoughtfully designing and maintaining a standard platform that everyone can use – existing, new and future vendors, researchers, and analysts alike. To be a standard, it needs to be shared. Because these standards are open, they can be used by anyone to innovate based on these standards providing more value back to society.
Examples of Standards
There are many examples of successful standards, especially in the tech industry. Here are a few of them.

Figure 1. An early illustration of a Langstroth hive as discussed in his book, The Hive and the Honey-bee.
Langstroth Hive: Its development along with similar standard hives in the 1850s revolutionized beekeeping. Discovering the importance of “Bee Space” and having standard sizes of hives and frames allowed for the free exchange of equipment, bees, and other materials between hives and beekeepers, making it much easier to scale and manage bigger beeyards. This also lowered production and maintenance costs for hives considerably.
Structured Query Language (SQL): This is a database manipulation and definition language developed in the 1960s and 1970s as a free and open standard that is still widely used today; in fact, it is perhaps one of the most popular computer languages3 ever created. As new languages have grown in popularity, SQL is often merged with them to support common storage infrastructure.
Transmission Control Protocol/Internet Protocol (TCP/IP): This is another standard that has had a large impact on society as it governs transmission of data across the internet. As an open standard it has become adopted for most traffic online, making moving information across the internet feasible and enabling the creation of the World Wide Web.
HTML and XML
Two of the most successful standards in recent history are HTML and its semantic twin XML. Most of our readers will be familiar with HTML, which stands for Hypertext Markup Language. This is the standardized web language that makes browsing on the internet seamless and enjoyable. Regardless of the browser (within reason), anyone from anywhere can see essentially the same thing on their device, independent of the underlying technology or system they are using.

Figure 2. Sample XML Code for a beekeeper application developed by Walter Haefeker.
The reason is that HTML is a markup language. That is, it encodes meta-tags (information about the content) focused on how to display the content in a standard consistent way. For example, it might have a tag like this <b>TEXT</b> (makes text bold) embedded around the words, pictures, and tables we see. As users, we do not see the meta tags, just the content. However, it is the meta-tags that tell your browser where and how to display the content you want to see, regardless of the device you are using. I think most of us would agree that this little innovation has had a very large and significant impact on our society. Though the standard has evolved over time (we are now mostly using HTML 5.0), it has revolutionized how we work, live, and communicate.
XML is the less well known, but no less important, little sister to HTML. Whereas HTML focuses on how to display content on your screen in a standard way, XML focuses on defining what that data means. This is a very important point, so let me give emphasis here.
XML is also a markup language, known as Extensible Markup Language. It focuses on marking up the meaning of the data whereas HTML marks up the formatting of the information to tell a computer how to display it in a standard format, e.g. color, position, font size. But it leaves it to the person to interpret the meaning of the information. Put another way, XML focuses on the meaning of the data whereas HTML focus on the format the content that is displayed.
The Semantic Web
XML uses tags very similar to HTML where a person or computer can read and interpret the meaning of the data. That is, rather than tag a block of text to make it appear bigger or smaller, red or green, it tags a block of text in a way that another computer can read the meaning of the data. That is it “tags” blocks of text to show structure, relationships, and other semantic attributes of the data so the next information system knows how to receive, store and process the data. It is a protocol for one machine to talk to another and convey the meaning of the data. For example, you might tag a hive id with a tag like this: <Hive_ID> #34543 </Hive_ID> so the next system knows that the text (or numbers) in between identify a hive.
Regardless of where it is located in the document, or the system being used to transmit the data, when the computer sees that tag, it knows that that is the hive id and can move it to the proper place in the local database or information system and process it accordingly. This concept, on conveying not only the form, but also the meaning of content has become known as the Semantic Web, and XML is a critical part of it. The term is derived from the ancient greek word sema, to sign or signal meaning.
Everyday XML
Most of us use XML everyday, perhaps without knowing it. XML has become the default means of data exchange for many industries, including:
RSS, Atom, SOAP, SVG, and XHTML
Industry data standards, e.g. HL7, OTA, NDC, FpML, MISMO etc. are based on XML
Data interchange in internet applications
In fact, even Microsoft Office now uses XML as a portable data standard: it is actually the x in .docx, xlsx, pptx, etc.
XML vs JSON
While there are newer technologies like JSON (JavaScript Object Notation), XML remains a leading technology due to its history, flexibility, and adaptability given the low computational overhead needed to transmit data such as that which you might find in a bee yard. Additionally, XML permits annotating the data with metadata (data about data) such as the equipment used, last calibration date, precision and other facts concerning the providence of the data. This provides a richer source for data over the long term. It is also human readable and easy to code without extensive computer skills, making it easy for those who wish to add their data to a repository to do so. Consequently, it is likely the best choice for data related to bees and beekeeping.
Exploring How XML Can Help Beekeepers
Currently, all hardware vendors for smart hive tools use their own unique data standard mostly locked away in a proprietary data management system. Moreover, at the technical level of the sensors, they use different calibration techniques from different equipment to measure what is happening in the hive. These calibration techniques are generally stored in their native format – largely unreadable to humans – and require software applications to convert the sensor reading to something we can understand.
Different vendors will do this differently and calibration techniques are not automatically interchangeable without translation. Notably, different vendors also track different things and the same things in different ways. For example, let’s look at temperature sensors. A vendor could measure temperature with a variety of tools, such as thermocouple, RTD (resistant detector), thermistors, semiconductor sensors, infrared sensors or others4. Additionally, a vendor can measure the inside top, bottom, center, left, or right of the hive or outside the hive in various locations. A vendor can also have different time frequencies for reporting and different units of measurement.
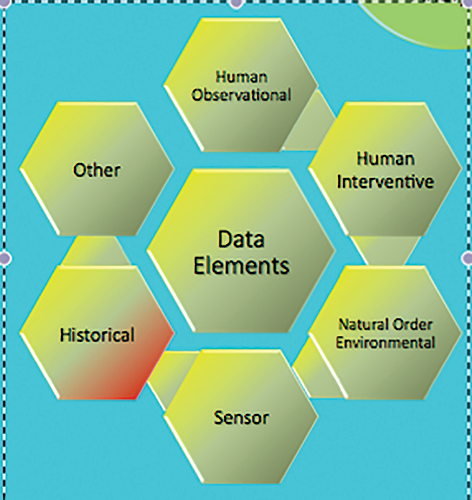
Figure 4. High Level Data Taxonomy.
Each of these measurements can mean different things to the hive and may need to be recorded in a different way. If we just say “this is the temperature,” we don’t know which one or how it was measured. Additionally, sensors are just part of the equation. There are hundreds of elements that can be measured; however, it is likely that only a few are important. Figure 4. shows a taxonomy of a few categories of elements we should measure. Each category holds many more. We then need to think about how best to measure a particular element. At this point, we are still learning which ones are important to what. Until we know more, we need to measure as many as we can.
XML will help beekeepers by defining data, along with the meaning of that data, so that it can be shared, pooled, analyzed, and used to build better tools for beekeepers everywhere. BeeXML.org, founded by Walter Haefeker, is a non-profit group aimed at working with all the stakeholders to build and host a data standard that any beekeeper, vendor, or researcher can use. The organization does not make tools or analyze the data, but rather provides a framework and XML library that can serve as a building block for others (like HiveTracks.com or Arnia) to use to make sure their data is compliant and aggregatable. Future upgrades can incorporate the same standard. Likewise, new open source manufacturers can apply it, all of which makes the data more readily available to beekeepers.
Governmental institutions, academic research projects, as well as breeding programs of beekeeping associations inevitably gather data about bees and beekeepers. Unfortunately, these databases become data islands and the information is of limited value for the beekeeping community as a whole. BeeXML is intended to be the answer to this problem. The project is not about creating a central database. Rather, XML is a self-describing data format that can allow for the exchange of data.
In order to create an XML standard, it is necessary to agree on what data is collected on a particular topic. If we apply a self-describing structure, it makes the exchange much more flexible than it would be with rigid table definitions. In addition, there are countless development environments for ready-made software libraries to read and write XML. Once we have a standard for a particular topic, the existing databases can be provided with XML interfaces. This in turn would later allow for a meta database, where it will be possible to query all connected databases via a common interface.
While still in its early stages, specific objectives include the following:
- Key Data Identification: Identify key data that is critical in developing solutions to problems faced by bees and beekeepers.
- Data Source Identification: Identify and aggregate existing sources of data to help build and adapt the standard, including data collected from beekeepers, researchers, industry partners and governments. For example, the European Food Safety Authority (EFSA) published a very helpful document defining common terms and definitions related to bees and other pollinators that can be a nice starting point for data definitions. It is located here: http://www.efsa.europa.eu/en/supporting/pub/en-1423
- Define XML Library: Build, define, and publicly release the XML library standard with key stakeholders here and abroad. This standard could then be downloaded and used by beekeepers and researchers globally.
- Data Collection System: While it is not the purpose of BeeXML.org to build its own collections system, this standard will allow for others to do so. Such a system (or group of systems) could collect, manage, and store this information in a way that will be accessible to researchers and data scientists.
Data Diversity
One of the key benefits of a standard like XML is that it is, as its name implies, extensible. This means it is easily extendable to include multiple data points. One of the key advantages of XML is its ability to be user-defined. That is, if you have existing data, you can create a meta-tag. A meta-tag contains information about the data for the computer to process, from meta, providing information about itself.
This means that data we already have can be captured, encoded and transmitted in a standard format that can be analyzed today, which is important for two reasons: 1) we will not have to wait as long for tools like the Genius Hive to emerge if we can use what we have; 2) since we do not yet know which data will be most predictive, we can extend and adapt the standard overtime.
Together, these two features allow for more Data Diversity, increasing the chances of us finding useful information during the data analysis phase. Additionally, because it is extendible, future data may be added to the repository for things we may not even be able to measure today, but could become very important over time as remote sensing technology evolves.
Helping With This Effort
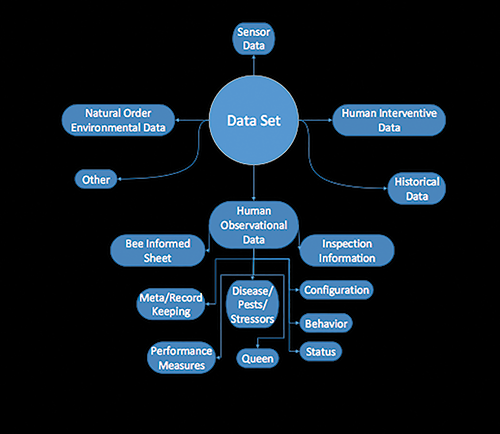
Figure 3. A sample of a few data sources.
Contributions to the BeeXML initiative are welcome from many sources. If you care about bees, there are many ways you can help with this important effort. Here are some ideas:
- Vendor: If you are a provider of hive tracking software or beekeeping hardware, please consider providing sample data sets similar to figure 3, which would be helpful for us to surface the commonalities of the proprietary databases and adjust the standard.
- Researcher: If you are a scientist who has created databases to keep track of the data from the hives in your experiments, please consider providing sample data sets to help define a useful standard.
- Funder of Research: If you are part of a government agency or a commercial enterprise and you are funding bee-related research, please consider making it a requirement that all project data be handled in BeeXML. If the standard does not cover your type of data yet, submit a sample data set to drive the standardization effort in this direction.
- Donor: If you are a donor, please consider donating funds to support the researchers, technicians, and publicity and data library development
- Farmer: If you are a farmer, please consider helping us expand this effort to include data from farms, given that bees are responsible for pollinating any of the crops we grow, and because the health and vitality of bees are greatly affected by their environment in the field. Farmers could “advertise” sites with pollination requirements, foraging opportunities as well as threats to bee health or potential contamination sources for hive products. Based on the data beekeepers can decide where to place their hives.
- Beekeeper: If you are beekeeper and a customer of hive tracking tools, please insist on being able to import and export your data using BeeXML. It is not in your interest to become a captive user of a certain platform because your data are stuck in a proprietary format.
Our message to everyone is to please encourage the adoption and use of this data standard and the data science that can be built on it by adopting and supporting it when you can and, when you find something that works, sharing it with others.
Acknowledgments
We would like to acknowledge the hard work of our volunteers trying to make this vision of a data standard free for all beekeepers. Updates on our progress and the participants working hard to make it a reality can be found at https://www.apimondia.com/en/activities/working-groups
Finally, special thanks to Project Apis m. for supporting a portion of this work with a Healthy Hives 2020 grant and to the editors of Bee Culture for publishing this work. These efforts would not have been possible without visionary groups like this one providing support and resources.
1https://en.wikipedia.org/wiki/Tower_of_Babel
2German Late Medieval (c. 1370s) depiction of the construction of the tower.
3Technically it is a data definition and data manipulation language, and not a complete programming language in the modern sense.
4https://www.elprocus.com/temperature-sensors-types-working-operation/
Joseph Cazier is the Chief Analytics Officer for HiveTracks.com and the Director of the Center for Analytics Research and Education at Appalachian State University. You can reach him at joseph@hivetracks.com.
Walter Haefeker is a professional beekeeper from Upper Bavaria, board member of the German Professional Beekeepers Association , as well as President of the European Professional Beekeepers Association.
Edgar Hassler, Ph.D is the Associate Director for Technology at the Center for Analytics Research and Education at Appalachian State University. You can reach him at hassleree@appstate.edu

